


 皆さま、こんにちは、ソニー・ミュージックマーケティングユナイテッドのたまごです。
普段は、アーティストのデジタルマーケティングを行う部門で、アドホックなデータ分析や市場リサーチなどを担当しています。
我々のチームでは、分析用途に応じて、SNSや音楽配信サービスなど、さまざまなサービスからデータ収集を行っています。
皆さま、こんにちは、ソニー・ミュージックマーケティングユナイテッドのたまごです。
普段は、アーティストのデジタルマーケティングを行う部門で、アドホックなデータ分析や市場リサーチなどを担当しています。
我々のチームでは、分析用途に応じて、SNSや音楽配信サービスなど、さまざまなサービスからデータ収集を行っています。
以前に当ブログでは、YouTube Analytics APIを用いたアーティストチャンネルのデータ取得について紹介しました。 ただ、これはあくまで自身が認証情報を把握しているチャンネルから詳細な統計データを取得する方法であり、他人が管理しているチャンネルからデータを取得する方法については触れていませんでした。 今回は、YouTube Data APIを用いた、より一般的なYouTube上のデータ取得の方法について紹介します。
なぜYouTubeの(自身のチャンネル以外の)データが欲しいのか?
Analytics APIの記事でも紹介した通り、音楽業界では、A&R(アーティスト&レパートリー)やプロモーターと呼ばれる人たちが、日々アーティストのプロモーションを行っています。特にYouTubeは、MVやその他の企画動画などを発信する場として、プロモーションの最も大事なツールの一つとなっています。
A&Rやプロモーターたちアーティストチームは、投稿するコンテンツに日々頭を悩ませており、競合チャンネルの人気動画の調査やトレンド追跡といった、YouTube上の一般的な分析は非常に需要が高くなっています。
YouTube Data APIは、こうした自身のチャンネル以外に目を向けたYouTube上のデータ分析において力を発揮します。
デモンストレーション
今回は、指定したチャンネルの全動画の再生数・いいね数・コメント数を取得することを目指します。
1. APIキーの取得
まず事前準備として、Data APIを活用するための認証情報を発行します。
Google Cloud Platform上でプロジェクトを作成し、YouTube Data APIを有効化してAPIキーを発行することになります。 具体的な手順については以下▶を展開の上ご参照ください。
具体的な手順例
Google Cloud Platformのコンソールへアクセス。 必要に応じて新しいプロジェクトを作成。プロジェクト名は何でも良いため管理しやすいものに。
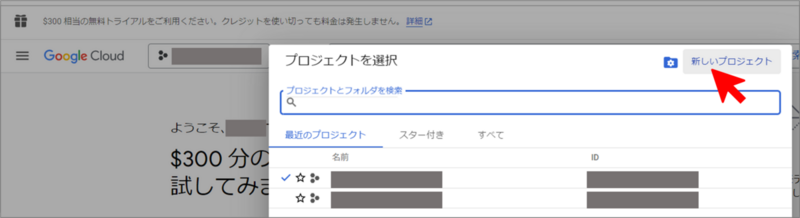
プロジェクトを選択して、画面左の「APIとサービス」>「有効なAPIとサービス」へ移動。
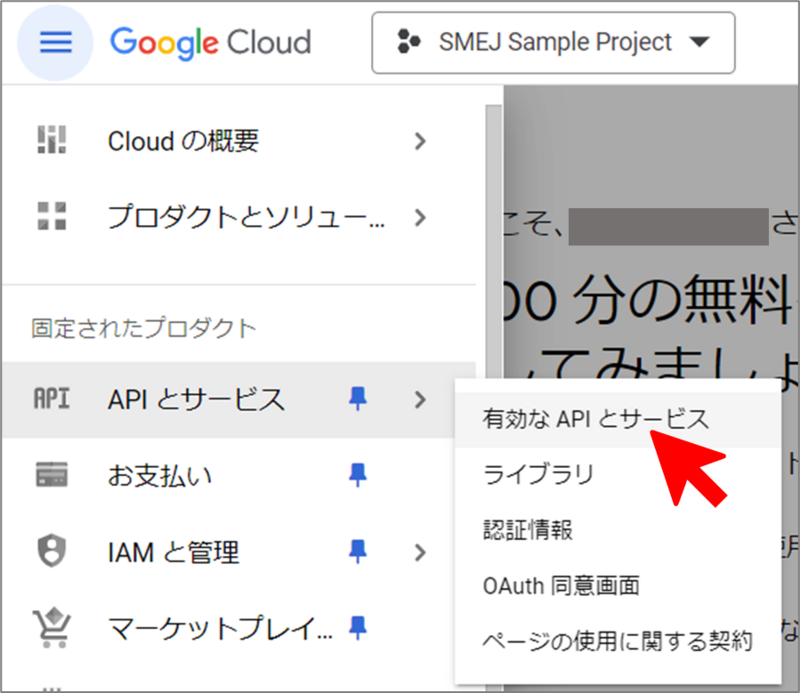
画面上部の検索ボックスから”YouTube Data API”を検索。
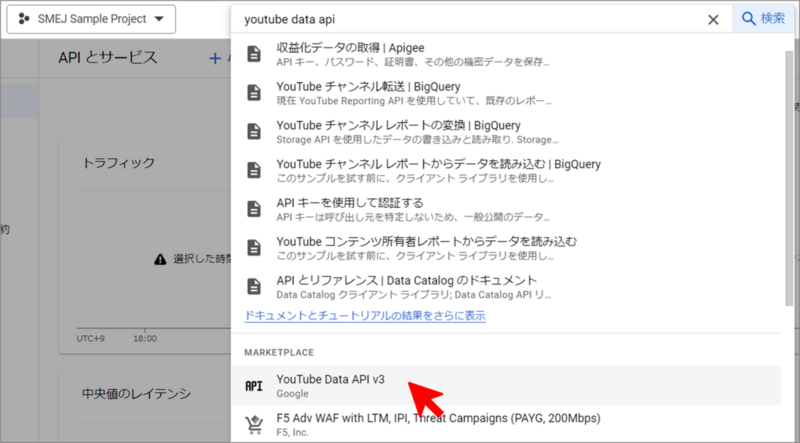
「有効にする」をクリック。
画面左のメニューから「認証情報」画面へ移動。
画面上部の+ボタンから「APIキー」を作成。APIキーと呼ばれる文字列が表示されるため、後ほど利用するために控えておく。
2. データ取得
Data APIのsearch, playlistItemsという2つのリソースを利用する方針で進めます。
尚、以下のサンプルスクリプトは、簡単のためにエラー処理などを含まない形となっている点ご了承ください。
Search: 指定したチャンネルの全動画のvideoIdを取得
channelIdというYouTube上のチャンネルの識別子から、対象チャンネルからアップロードされた全動画のvideoIdを取得します。 ※videoIdとはYouTube上の動画識別子のこと。Analytics APIの記事も参照。
[補足1]channelIdの取得方法について
channelIdとは、”UC”から始まる、YouTube上のチャンネル識別子に相当する文字列です。 少し前までYouTubeのチャンネルページのURLから確認ができたのですが、最近は同じ欄にユーザー名が表示されるようになり、少し工夫しないと取得ができなくなってしまいました。
ネット上で少し調べると有志の方が作成されたフォームも出てくるので、一旦良きやり方で取得しておきましょう。 ご参考までに、本稿の最後でもData APIを用いた簡単な取得方法について紹介しています。 [補足1終わり]
[補足2]Quota costについて
Searchリソースはリクエスト当たりのquota cost(APIの通信容量)が大きいため、複数チャンネルでデータ取得を試みる場合など、大量の動画情報を取得する際は、上記の方針だと通信制限に引っかかってエラーを吐くことがあります。
channelsリソースで指定チャンネルのアップロード動画のプレイリストのplaylistId取得→playlistItemsスコープで取得されたplaylistId内の全動画のvideoId取得 という流れの方がquota costがお得ですが、1ステップ増えるので今回は手っ取り早くsearchスコープで実装しています。
気になる方はDocumentも参照しつつ手を動かしてみてください。[補足2終わり]
APIの実行に当たっては、パラメータで欲しい情報を指定して、各リソースに対応したURLにGETリクエストを投げることになります。
ドキュメントも参照しつつ、以下のリクエストを投げて出力を見てみましょう。
import requests from pprint import pprint #検索したいチャンネルのchannelId channelId = 'UCXXXXXXXXXXXXXXXXXXX' #SearchリソースのリクエストURL指定 url = 'https://www.googleapis.com/youtube/v3/' resource = 'search' request_url = url + resource #パラメータ設定 ##指定したchannelIdから投稿された動画情報を投稿日順に取得する方法 params = { 'key': 'YOUR_API_KEY', #1.で取得したAPIキーを入力 'part': 'id', #videoIdを含むプロパティ 'channelId': channelId, 'order': 'date', #検索結果を投稿日順に表示 'type': 'video', #動画のみを検索(プレイリストなどを検索結果に含まない) 'maxResults': 50, #1リクエストあたりの検索結果の動画数(デフォルトは5、最大で50まで設定可能) } #リクエスト実行 search_result = requests.get(request_url, params=params) #json形式の結果を格納 search_result_json = search_result.json() #結果の確認 pprint(search_result_json)
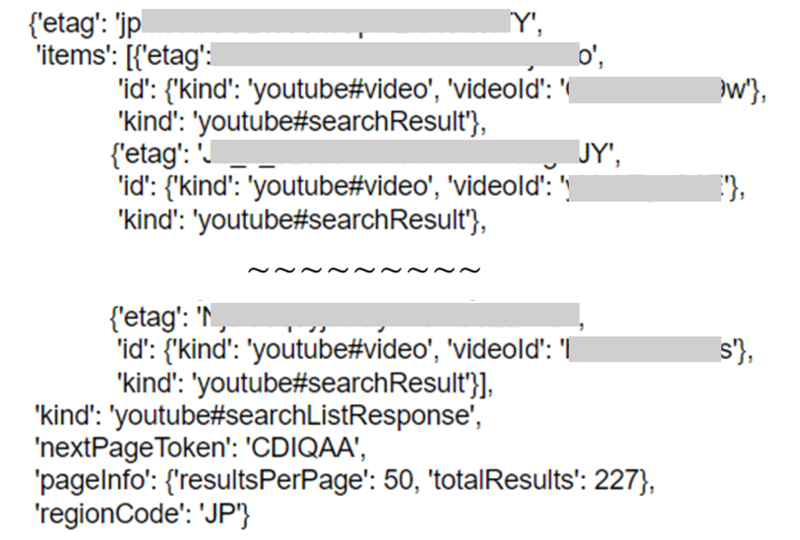
どうやら、items値の中にリスト形式で各動画の情報が入っていそうです。 ただ、pageInfo値を見ると、どうやらチャンネルの全動画(この例では227件)のうち、50件しか取得ができていないように見えます。 実際、item値のリストの要素数は50個しか無いことが確認できます。
# データ取得できた動画数 num_search_result = len(search_result_json['items']) print(num_search_result) # 50
これはAPIの仕様上、一度のリクエストで最大50個動画ずつしか情報を取得できないことが原因です。 もっと沢山の動画の情報を取得するためには、pageTokenと呼ばれるパラメータを更新しつつ、逐次的にリクエストを投げる必要があります。
この点を踏まえて、pageTokenの更新をしながらループ処理を回し、指定したチャンネルの全動画のvideoIdをvideoIdListというリスト変数へ逐次的に格納していきましょう。
import requests #検索したいチャンネルのchannelId channelId = 'UCXXXXXXXXXXXXXXXXXXX' #SearchリソースのリクエストURL指定 url = 'https://www.googleapis.com/youtube/v3/' resource = 'search' request_url = url + resource #空のリストを準備 videoIdList = [] #pageTokenの初期化 pageToken = None while True: #パラメータ設定 params = { 'key': 'YOUR_API_KEY', #1.で取得したAPIキーを入力 'part': 'id', #videoIdを含むプロパティ 'channelId': channelId, #検索したいチャンネルのchannelId 'order': 'date', #検索結果を時系列順に表示 'type': 'video', #動画のみを検索(プレイリストなどを検索結果に含まない) 'maxResults': 50, #1リクエストあたりの検索結果の動画数(デフォルトは5、最大で50まで設定可能) 'pageToken': pageToken #リクエストのトークン } #リクエスト実行 search_result = requests.get(request_url, params=params) #json形式の結果を格納 search_result_json = search_result.json() #videoIdの抽出 for item in search_result_json['items']: videoIdList.append(item['id']['videoId']) #検索結果を全て表示できていない場合はpageTokenを更新 if 'nextPageToken' in search_result_json: pageToken = search_result_json['nextPageToken'] else: break #データ取得した動画数の確認 print(len(videoIdList)) # 227
今度は全動画のvideoIdがうまく取れていそうです!
※チャンネル上で非公開の動画がある場合など、pageInfo > totalResultsの総動画数と結果が微妙にずれることがあります。どうせ非公開動画の統計データは取れないので、ここの取得漏れはあまり気にせず大丈夫です。
Videos: 各videoIdに紐づく動画の統計データを取得
上記の手順で取得されたvideoIdたちについて、videosリソースを用いて統計データを取得していきます。 まずは試しに1動画だけリクエストを投げて出力の形式を見てみましょう。
from pprint import pprint #1動画のvideoId videoId = videoIdList[0] #VideosリソースのリクエストURL指定 url = 'https://www.googleapis.com/youtube/v3/' resource = 'videos' request_url = url + resource #パラメータ設定 params = { 'key': key, 'part': 'snippet,statistics', 'id': videoId } #リクエスト実行 videos_result = requests.get(request_url, params=params) videos_result_json = videos_result.json() #結果の出力 pprint(videos_result_json)
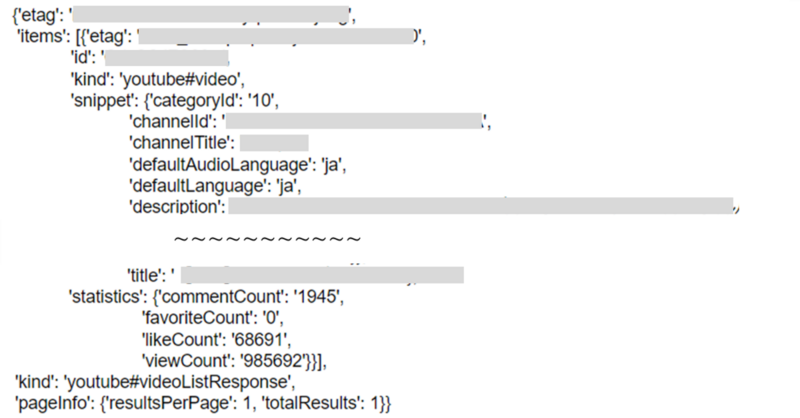
どうやら、items値の中に各動画の情報がリスト形式で入っていそうです。 以下では、Searchリソースから取得されたvideoIdたちについて、以下の情報をDataFrameの形で格納することを考えましょう。
- snippet > title
- statistics > commentCount, likeCount, viewCount
基本的には上記のデータを格納するようループを回すだけです。 1つポイントを挙げるとすれば、videoIdパラメータは50動画までならカンマ区切りで一気にリクエストを投げることができるため(※2024年1月現在)、以下コードでは事前にvideoIdListを50個ずつのグループに再分割した上で、1グループごとにリクエストを投げています。 こうした方がリクエスト数が少なくなり、Quota costを抑えられます。
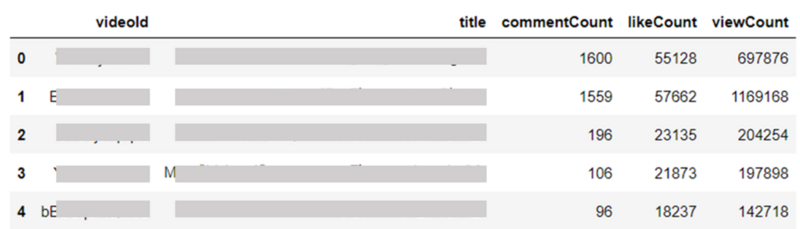
import pandas as pd #videoIdListの分割 videoIdList_splitted = [] for i in range(0, len(videoIdList), 50): videoIdList_splitted.append(videoIdList[i:i+50]) #VideosリソースのリクエストURL指定 url = 'https://www.googleapis.com/youtube/v3/' resource = 'videos' request_url = url + resource #データを追加する空のリストを準備 data = [] #各グループごとにリクエスト実行 for videoId_grp in videoIdList_splitted: #パラメータ設定 params = { 'key': key, 'part': 'snippet,statistics', 'id': ','.join(videoId_grp) } #リクエスト実行 videos_result = requests.get(request_url, params=params) videos_result_json = videos_result.json() #動画情報の抽出 for item in videos_result_json['items']: videoId = item['id'] title = item['snippet']['title'] commentCount = item['statistics']['commentCount'] likeCount = item['statistics']['likeCount'] viewCount = item['statistics']['viewCount'] #結果を逐次的に追加 data.append([videoId, title, commentCount, likeCount, viewCount]) #DataFrameの形で出力 columns = ['videoId', 'title', 'commentCount', 'likeCount', 'viewCount'] df = pd.DataFrame(data, columns=columns)
dfの中身を見てみると、想定通りチャンネルの全動画の統計データが取得できていそうです!
最後に
YouTube Data APIを用いた、簡単なデータ取得のデモンストレーションを見てみました。
今回ご紹介したのはあくまで使い方の一部であり、Data APIを用いることで非常に広範な分析を行うことができます。 例えば、Searchリソースではチャンネルを指定せずに任意のクエリの検索結果を表示することもできますし、Commentsリソースからは各動画についたコメント文の取得も可能です。 興味のある方は公式ドキュメントを眺めてみると思わぬ発見があるかもしれません。
尚、自身が管理していないチャンネルの情報を取得するということで、データの取り扱いには十分な注意が必要です。データ保持期間や分析への利用可能範囲についてはDeveloper policyに詳しい記載がありますので、APIの使用前には目を通されることをおすすめします。
Tips: channelIdの取得方法例
以下コードでは、Videoリソースを用いて、対象チャンネルから投稿された任意の動画のvideoIdから投稿元のchannelIdを取得しています。
import requests ### 対象チャンネルから投稿された任意の動画のvideoIdを入力 ### videoId = 'XXXXXXXX' #VideosリソースのリクエストURL指定 url = 'https://www.googleapis.com/youtube/v3/' resource = url + 'videos' #パラメータ設定 params = { 'key': key, 'part': 'snippet', 'id': videoId } #リクエスト実施 videos_result = requests.get(resource, params=params) videos_result_json = videos_result.json() #channelIdの抽出・出力 channelId = videos_result_json['items'][0]['snippet']['channelId'] print(channelId)
