


 皆さまこんにちは。ソニー・ミュージックエンタテインメントで生成AIの調査・検討を行っているみみずくです。
皆さまこんにちは。ソニー・ミュージックエンタテインメントで生成AIの調査・検討を行っているみみずくです。
昨今、画像認識ができるAIは多くの場面で利用されています。たとえば、事故防止のために標識を認識して自動車のディスプレイに表示するシステムや、施設内のセキュリティエリアへの入場を顔認証で行うシステムなどは既に我々の生活にもなじみつつあります。
もちろんエンタメ業界でも、画像認識AIが活躍する場面はたくさんあります。しかしながら実際に開発で使うとなると、まだまだハードルが高いような印象を持たれがちです。
そこで今回はGoogleが提供している機械学習サービスであるVision APIを用いて、画像認識AIをわかりやすい形で扱っていきたいと思います。 ※Vision APIの挙動など、ハンズオンの内容は記事執筆時点のものです。
目的の設定
ひとくちに画像認識と言っても、Vision APIでできることは多岐にわたります。
画像に写っている文字を認識する「テキスト検出」や、社名や商品名などのロゴを検出する「ロゴ検出」、画像を構成している色を抽出する「画像プロパティ」、画像に何が写っているのかを識別する「ラベル検出」、人間の顔と表情を検出する「顔検出」など、公式に11もの機能がサポートされています。(詳細は公式ドキュメントを参照)
今回の記事ではソニーミュージックで考えうるユースケースの一つとして、「イベント会場に来ているお客さんの満足度を『顔検出』機能を利用して測定する」というものを想定します。 本記事の最後には、ウェブカメラ越しに映るこちらの表情が判定されるプログラムができあがっているはずです。
なお、実際にはリアルタイムでカメラ内に映り込んだ表情を検出できれば便利なのですが、ここでそれをやってしまうとクレジットを大量に消費してしまうので、今回は静止画を撮影してその中に写っている人の顔から表情を検出する仕様で作っていきたいと思います。
Vision APIの準備
まずは、Vision APIを使えるようにするための準備が必要です。
- Google Cloud Consoleにアクセスし、「プロジェクトセレクタ」から「プロジェクトを作成」を選択し、適当なプロジェクト名をつけます。(ここでは仮にFaceDetectorとします)
- 作成したプロジェクトの「ダッシュボード」>「APIの概要に移動」>「ライブラリ」から「APIライブラリへようこそ」という画面を呼び出します。検索欄に「Cloud Vision API」と入力し、Cloud Vision APIを有効にします。
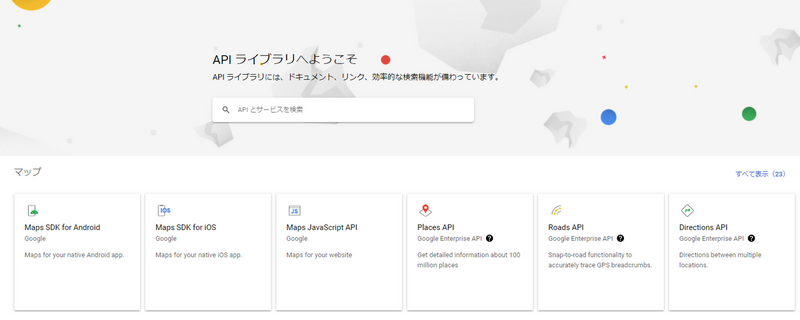
- APIにアクセスするために必要な「サービスアカウント」を作成します。「Identity and Access Management (IAM) API」がオンになっているのを確認した上で、「サービス アカウントの作成」ページにアクセスします。
適当な「サービスアカウント名」を入力することにより、サービスアカウントが作成されます。 - 作成したサービスアカウントのための認証キーを作成します。プロジェクトを選択し、サービス アカウントのメールアドレスをクリックしてから、「キー」タブをクリックします。現時点では「表示する行がありません」となっているはずなので、「鍵を追加」ボタンから「新しい鍵を作成」します。鍵のタイプは「JSON」で構いません。「作成」をクリックすると、サービスアカウントキーファイルがダウンロードされます。なお、鍵ファイルをダウンロードした後、再度ダウンロードすることはできませんので注意しましょう。
- コンソールの「課金」からGoogle Cloudの請求先アカウントを設定します。今回は無料で利用可能な範囲で動かしていく予定ではありますが、Google Coudの仕様上請求先アカウントを設定する必要があります。FaceDetectorと作成した請求先アカウントが連携されていることを確認してください。
- 最後に、手順4でダウンロードしたJSONファイルを自身のGoogleドライブ上にアップロードします。今回は「visiontest」というフォルダを作成し、その中に「credentials.json」という名前で置いておきます。
以上でCloud Vision APIを使用する準備が完了しました。
スクリプトの作成
準備
ここからは、Web上でPythonを実行できるGoogle Colaboratoryを用いてVision APIを実行していきたいと思います。
Colaboratoryのページにアクセスし、「ノートブックを新規作成」をクリックします。
 Google ColaboratoryでPythonのスクリプトを使うには、pipをインストールする必要があります。そのため、最初に以下を入力します。
Google ColaboratoryでPythonのスクリプトを使うには、pipをインストールする必要があります。そのため、最初に以下を入力します。
!pip install --upgrade google-cloud-vision
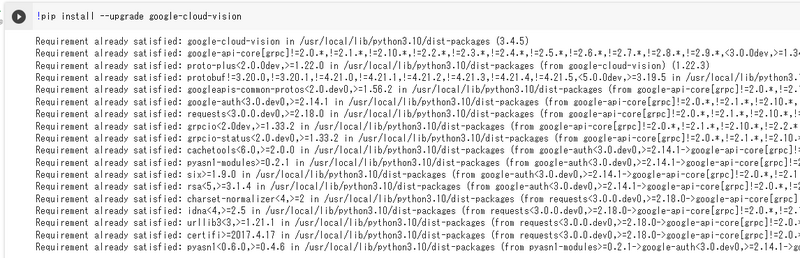 上の画像のような実行結果になっていればOKです。
上の画像のような実行結果になっていればOKです。
続いて、下にコードセルを追加し、ヘッダとしていくつかの便利なパッケージを読み込みます。
# Google Driveをマウント from google.colab import drive drive.mount('/content/gdrive') # imshowサポートパッチのインポート from google.colab.patches import cv2_imshow # dnn用 from IPython.display import display, Javascript from google.colab.output import eval_js from base64 import b64decode # その他パッケージ import imutils import numpy as np import matplotlib.pyplot as plt import cv2
「Mounted at /content/gdrive」などと表示されれば成功です。
ColaboratoryからVision APIにアクセスできるようにする
Vision APIを叩くためには、先ほどGoogleドライブ上にアップロードしたサービスアカウントキーファイルを読み込む必要があります。 たとえば、「visiontest」というフォルダ内に「credentials.json」という名前で保管してあるのなら、次のようなコードで呼び出すことができます。
import os import os.path import errno from googleapiclient import discovery from oauth2client.client import GoogleCredentials cred_path = '/content/gdrive/My Drive/visiontest/credentials.json' if os.path.exists(cred_path) == False: raise FileNotFoundError(errno.ENOENT, os.strerror(errno.ENOENT), cred_path) os.environ["GOOGLE_APPLICATION_CREDENTIALS"] = cred_path
これでGoogle ColaboratoryからVision APIにアクセスすることが可能となりました。
ウェブカメラとの接続
続いてGoogle Colaboratoryが公式で配布している、Webカメラを使うためのスニペットを読み込みます。 画面左下のメニューにある「< >」のようなマークをクリックし、コード スニペットを表示します。 その中にある「Camera Capture」を選択、「挿入」します。 スクリプトを順番に実行していくと、ウェブカメラが実行され、画面上に自分の顔が表示されると思います。この状態で「Capture」と書かれたボタンを押せば写真を画像データとして一時保存することができます。これで、ウェブカメラの利用が可能となりました。
Vision APIでの画像認識
次に、いよいよ画像認識のコードを書いていきます。
def detect_faces(path): """Detects faces in an image.""" from google.cloud import vision import io client = vision.ImageAnnotatorClient() with io.open(path, 'rb') as image_file: content = image_file.read() image = vision.Image(content=content) response = client.face_detection(image=image) faces = response.face_annotations # Names of likelihood from google.cloud.vision.enums likelihood_name = ('UNKNOWN', 'VERY_UNLIKELY', 'UNLIKELY', 'POSSIBLE', 'LIKELY', 'VERY_LIKELY') for face in faces: print('anger: {}'.format(likelihood_name[face.anger_likelihood])) print('sorrow: {}'.format(likelihood_name[face.sorrow_likelihood])) print('under_exposed: {}'.format(likelihood_name[face.under_exposed_likelihood])) print('blurred: {}'.format(likelihood_name[face.blurred_likelihood])) print('headwear: {}'.format(likelihood_name[face.headwear_likelihood])) print('joy: {}'.format(likelihood_name[face.joy_likelihood])) print('surprise: {}'.format(likelihood_name[face.surprise_likelihood])) vertices = (['({},{})'.format(vertex.x, vertex.y) for vertex in face.bounding_poly.vertices]) print('face bounds: {}'.format(','.join(vertices))) if response.error.message: raise Exception( '{}\nFor more info on error messages, check: ' 'https://cloud.google.com/apis/design/errors'.format( response.error.message)) detect_faces(filename)
ここでは「detect_faces」という名前の関数を定義し、その中でVision APIにウェブカメラで撮影した画像(filename)を送ると、AIが推定した表情と顔の位置がJSON形式で取得できるようにしています。
仮に、「Capture」ボタンでこのような画像が撮影できたとします。

次に最後のブロックを実行すると、以下のような結果が出力されます。
実行結果
anger: VERY_UNLIKELY sorrow: VERY_UNLIKELY under_exposed: VERY_UNLIKELY blurred: VERY_UNLIKELY headwear: VERY_UNLIKELY joy: VERY_LIKELY surprise: VERY_UNLIKELY face bounds: (579,617),(932,617),(932,1027),(579,1027) anger: VERY_UNLIKELY sorrow: VERY_UNLIKELY under_exposed: VERY_UNLIKELY blurred: VERY_UNLIKELY headwear: VERY_UNLIKELY joy: VERY_LIKELY surprise: VERY_UNLIKELY face bounds: (1138,345),(1548,345),(1548,822),(1138,822)
これは画像内に二つの顔があり、どちらもjoy(楽しい)の表情をしているに違いない、という意味あいとして理解できます。 一方、anger(怒り)やsorrow(悲しみ)などの感情に関しては、VERY_UNLIKELY(=全くそうではない)という判定が出ています。
これだけでも十分当初の目的を達成できたといえるのですが、せっかくなのでもう少し扱いやすいように出力結果を整形してみたいと思います。
さらなる工夫
仮に画像に映っている人の「joy」の度合いの平均値が高いほどお客さんの満足度が高いと考えましょう。 Vision APIの表情の推定は、「UNKNOWN」、「VERY UNLIKELY」、「UNLIKELY」、「POSSIBLE」、「LIKELY」、「VERY LIKELY」の6段階で行われます。 これらを数値化することを考えて、以下のような表を作ってみました。
| Vision APIによる「joy」の評価 | スコア |
|---|---|
| UNKNOWN | なし |
| VERY UNLIKELY | 0 |
| UNLIKELY | 25 |
| POSSIBLE | 50 |
| LIKELY | 75 |
| VERY LIKELY | 100 |
写真に写っている人の表情が「joy」である可能性が高いほど、高いスコアが記録されます。 一方、表情が読み取れなかった(=UNKNOWN)の場合には、スコアが記録されません。 このような形で、写真に写っている人の表情をスコア化してみましょう。
detect_facesの関数を次のように書き換えます。
def detect_faces(path): """Detects faces in an image.""" from google.cloud import vision import io client = vision.ImageAnnotatorClient() with io.open(path, 'rb') as image_file: content = image_file.read() image = vision.Image(content=content) response = client.face_detection(image=image) faces = response.face_annotations # Names of likelihood from google.cloud.vision.enums likelihood_name = ('UNKNOWN', 'VERY_UNLIKELY', 'UNLIKELY', 'POSSIBLE', 'LIKELY', 'VERY_LIKELY') face_score = {'VERY_UNLIKELY':0, 'UNLIKELY':25, 'POSSIBLE':50, 'LIKELY':75, 'VERY_LIKELY':100} face_list = [] for face in faces: print('joy: {}'.format(likelihood_name[face.joy_likelihood])) face_list.append( face_score[format(likelihood_name[face.joy_likelihood])] ) print(face_list) print('満足度:'+str(np.average(face_list))) if response.error.message: raise Exception( '{}\nFor more info on error messages, check: ' 'https://cloud.google.com/apis/design/errors'.format( response.error.message)) detect_faces(filename)
ここでは、「face_score」という辞書を介して可能性評価とスコアを対応させ、スコアを「face_list」というリストに格納し、最終的にその平均値を出すことで満足度を算出できるようにしています。 たとえば5人の人物がいて、それぞれ「joy」である可能性が「VERY_LIKELY」「VERY_LIKELY」「LIKELY」「POSSIBLE」「VERY UNLIKELY」だった場合、スコアはそれぞれ「100」「100」「75」「50」「0」となり、満足度は平均値の65となります。
以上で、ウェブカメラからその場にいるお客さんの満足度を測ることのできる画像認識アプリは完成となります。
なお、今回はお客さんの満足度を測るというシナリオをユースケースとして取り上げましたが、実際に業務上で機械学習を使用する際には、顔写真という個人情報を扱っていく以上、よりセキュアで信頼性の高いツールを使っていく必要があるでしょう。
最後に
今回は写真に写っている人々の表情が「joy」である可能性にのみ着目して満足度を算出しましたが、もしかしたら「surprise(驚き)」の可能性が高いほど満足度が高かったり、「sorrow(悲しみ)」の可能性が低いほど満足度が高かったり、という要素を取り入れた計算方法も考えられるかもしれません。
皆さんも実際に手元でコードを書いてみて、より納得感のある計算方法がないか考えてみてください。
エンタメ業界でのAIの活用に興味がある方は、ぜひ一緒に面白い世の中を作っていきましょう!
