


 皆さんこんにちは。ソニー・ミュージックエンタテインメントで生成AIの調査・検討を行っているみみずくです。
皆さんこんにちは。ソニー・ミュージックエンタテインメントで生成AIの調査・検討を行っているみみずくです。
皆さんはコンピューター上で言語を処理するというと、どんな技術を想像するでしょうか。多くの方は、ChatGPTをはじめとする大規模言語モデル(LLM)をイメージされると思います。
しかし、LLMは必ずしも万能の存在ではなく、思ったように動いてくれないことも少なくありません。そんな時にはLLMに頼りきりにならず、あえて少し古い技術に当たってみることも有効です。
そこで、ここではLLMが登場するまで中心的な言語処理技術であった「Word2Vec(ワード・トゥ・ベック)」について紹介し、その中で行われている言語処理を皆さんに体験していただければと思います。
LLMも万能ではない
2024年現在、LLMを含む生成AI技術はトレンド真っ盛りの技術と言えるでしょう。
一方、過去の記事(https://tech.sme.co.jp/entry/2023/10/31/200000)でも紹介しましたが、LLMも万能というわけではありません。最近は数学能力が向上したり、知らないことを知らないと正しく答えるように進化したりしてはいますが、いまだに多くの限界が存在しています。
たとえば必要な計算機リソースが高くローカル環境で実行するハードルが高いことや、言語以外でのインプットがほとんどできないため細かな調整が難しいこと、仕組み上出現確率が高い単語から推論するので独創的な単語をアウトプットすることができないこと、精度の高いデータ分析や統計処理ができるわけではないこと、内部処理の大部分がブラックボックスのため人間がその計算プロセスを理解しづらいことなどが挙げられます。
Word2Vecとは
Word2Vecは、2013年にGoogleのトマス・ミコロフ率いる研究者チームによって開発された、単語をベクトル(数値の配列)で表現する手法です。自然言語処理の分野で革新的な技術として注目され、単語間の意味的な類似性や関係性を数値的に捉えることが可能になりました。
単語分散表現
Word2Vecでは、言葉を多次元のベクトルに変換して扱います。このベクトル空間では、意味が似ている単語同士が近い位置に配置されます。たとえば、king(王様)とqueen(女王)はベクトル空間上で近くに位置しています。
さらに、ベクトル化された単語は足し引きなどの数学的な処理が可能です。
有名なものでは、「王」 - 「男性」 + 「女性」 = 「女王」という計算結果が知られています。
このように、「文字・単語をベクトル空間に埋め込み、その空間上のひとつの点としてとらえる」ことを、「単語分散表現」と呼びます。
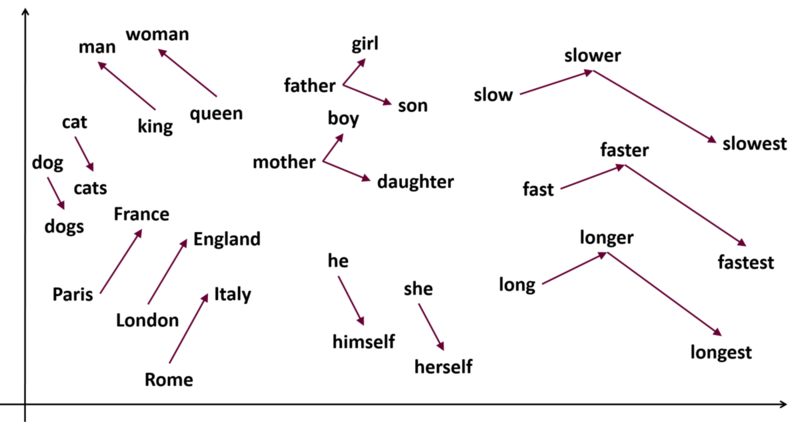
活用例
Word2Vecによって得られた単語ベクトルは、以下のようなタスクで活用できます。
- 類似単語の検索:意味的に近い単語を見つけることができます。
- 感情分析:単語のベクトルを用いてテキストの感情を判定します。
- 機械翻訳:異なる言語間での単語の対応関係を学習します。
なぜ重要なのか
従来の手法では、単語の意味をとらえることは困難でしたが、Word2Vecの登場により、言語の持つ複雑なパターンや関係性を数値的に扱うことが可能になりました。これは、自然言語処理だけでなく、データ分析や人工知能の分野全体においても大きな進歩と言えます。
LLMに対するWord2Vecの強み
大規模言語モデル(LLM)が近年注目を集めていますが、Word2VecにはLLMにはない独自の強みがあります。ここでは、Word2VecがLLMと比較して優れている点について解説します。
1.ブラックボックスでない明瞭な構造
LLMは多層のニューラルネットワークや自己注意機構を用いており、その内部は非常に複雑でブラックボックス化しています。一方、Word2Vecは比較的シンプルなモデル構造を持ち、その計算過程をトレースしやすいです。これにより、モデルの動作原理を理解しやすく、結果の解釈やデバッグが容易になります。
2. ユニークな単語のキャプチャ
LLMは大量のデータで事前学習されており、高頻度の単語やフレーズに最適化されています。そのため、確率上位にない珍しい単語や専門用語を適切に扱えない場合があります。Word2Vecはコーパス(言語全集。詳細は後述) 内のすべての単語をベクトル化するため、低頻度のユニークな単語でも意味的な関係をとらえることができます。
3. ファインチューニングの容易さ
Word2Vecはモデルが軽量で、学習に必要な計算資源も少ないため、特定のドメインや用途に合わせて容易にファインチューニングできます。小規模なデータセットでも短時間で再学習が可能で、迅速なプロトタイピングやモデルの最適化に適しています。一方、LLMのファインチューニングは高い計算コストと専門知識を必要とします。
4. リソース効率の高さ
Word2Vecはモデルサイズが小さく、計算コストも低いため、リソースが限られた環境でも使用できます。組み込みデバイスやモバイルアプリケーションなど、計算資源が制約される場面で特に有効です。
5. 解釈可能性とベクトル操作の直感性
Word2Vecのベクトル空間では、単語間の関係性が線形的に表現されます。例えば、「王」 - 「男性」 + 「女性」 = 「女王」といったベクトル演算は直感的に理解可能なものです。これらの特性はデータの分析や新たな知見の発見に役立ちます。LLMでは内部表現が複雑で、このような直感的な操作は難しいです。
6. 学習速度とデータ要件
Word2Vecは学習アルゴリズムが効率的で、必要なデータ量もLLMと比べて少なくて済みます。これにより、迅速なモデル開発や複数モデルの比較検証が可能です。LLMは膨大なデータと時間を必要とし、学習コストが高くなります。
7. 特定タスクへの適合性
特定のタスクや用途によっては、Word2Vecの方が適している場合があります。例えば、単語の類似度計算やクラスタリング(類似したデータのまとまりを調べる)など、単語レベルの解析が重要なタスクでは、Word2Vecが高い性能を発揮します。LLMは文脈理解や生成タスクに強みがありますが、必ずしもすべてのタスクで最適とは限りません。
これらの強みから、Word2Vecは現在でも有用なツールであり、用途や目的に応じてLLMと使い分けることで、効果的な自然言語処理が可能となるのです。
実際に使ってみよう
今回は、Google Cloudの提供する、Webブラウザー上でPythonを記述、実行できる機械学習教育・研究サービス 「Google Colaboratory(以下、Colab)」 を用いて実際のWord2Vecの動作を見ていきたいと思います。
まずColabを起動し、プロジェクトファイルを作成します。タイトルは適当に「Word2VecTest.ipynb」とでもしておきましょう。 Word2Vecは学習の段階でニューラルネットワークを使用するものの、高度な演算処理を必要としないので、ハードウェアアクセラレータは「CPU」のままで構いません。
まず、以下のコードで必要環境のセットアップを行います。 ここでは、Gutenberg Corpusという著作権切れの文学作品を中心とした英語文献が利用できるコーパスを読み込みます。
コーパスとは、自然言語の文章を大量に集め、コンピューター上で検索できるようにしたデータベースのことです。Gutenberg Corpusにはシェイクスピアのハムレットを含む古典的な作品が多く含まれています。
インポートしているgensimは、機械学習を用いて自然言語処理タスクを手軽に実装できるPythonライブラリで、Word2Vecモデルをトレーニングする際に使われます。
import gensim import nltk from nltk.corpus import gutenberg !pip install nltk # install nltk if it's not already installed nltk.download('gutenberg') # download the 'gutenberg' corpus nltk.download('punkt') # download the 'punkt' resource from nltk.corpus import gutenberg
次に、Word2VecモデルをGutenberg Corpusに基づいて学習するために以下のコードを実行します。
model = gensim.models.Word2Vec(gutenberg.sents(), vector_size=100, seed=0)
これは、100次元のベクトル空間としてWord2Vecのモデルをトレーニングしてあげるという意味のコードになります。 この処理は通常一分足らずで完了します。完了したら、次のコードでWord2Vecが機能していることを確認してみましょう。
model.wv["music"]
これは、「music」というワードがどのようなベクトルを持っているかを確かめるためのコードです。
array([-0.02268856, -0.23732288, …)などのように大量の数字が表示されれば成功です。それが、musicという単語が持つベクトルデータになります。 “”の中身を変えて、他の英単語でも試してみるといいでしょう。
次に、以下のコードで類似の単語を検索します。
model.wv.most_similar("music", topn=10)
これは、musicという言葉に似ている単語トップ10を表示するという意味のプログラムです。
以下のように出力されます。
[('bells', 0.8468937873840332),
('landscape', 0.8350112438201904),
('procession', 0.830817699432373),
('hotel', 0.8277840614318848),
('sunset', 0.8269937038421631),
('jealousies', 0.8155946135520935),
('archway', 0.8143562078475952),
('blaze', 0.8117223381996155),
('breeze', 0.8099266886711121),
('hulls', 0.8098711967468262)]
このように表示されることから、Gutenberg Corpus上では、「bells」や「landscape」が「music」と特に類似しているようです。
最後に、序盤で紹介した単語の足し引き演算を試してみたいと思います。
まずは有名な例にならって、「王」 - 「男性」 + 「女性」 をやってみたいと思います。
次のコードを実行します。
model.wv.most_similar(positive=['king', 'woman'], negative=['man'])
出力結果:
[('daughter', 0.6055667996406555),
('messengers', 0.5768982172012329),
('prophet', 0.5766884088516235),
('queen', 0.5745568871498108),
('Joseph', 0.5631714463233948),
('Solomon', 0.5588968992233276),
('Paul', 0.5581366419792175),
('son', 0.5578725337982178),
('captain', 0.5569366216659546),
('prince', 0.5452337265014648)]
どうやら、期待していたqueen(女王)は4番目で、daughter(娘)やmessengers(使者)の方が高く出たようです。 もう一つ試してみましょう。
model.wv.most_similar(positive=['moon', 'noon'], negative=['midnight'])
これは「月」 - 「真夜中」 + 「正午」という計算式を意味します。 私としては「太陽」が出てくることを期待しているのですが、どうなるでしょうか。
出力結果:
[('sun', 0.8190088272094727),
('sky', 0.8042715191841125),
('dew', 0.796305775642395),
('light', 0.7786010503768921),
('snow', 0.7666762471199036),
('clouds', 0.7655496597290039),
('stars', 0.7427696585655212),
('cool', 0.7380653023719788),
('windows', 0.7334594130516052),
('star', 0.7331791520118713)]
1番目にsun(太陽)が出てきました。これはWord2Vecがどのように動いているのか直観的に分かる好例だと思います。
Word2Vecには他にもさまざまな機能が用意されているので、思うままに触ってみるのもいいでしょう。
さらなる応用
上の例ではGutenberg Corpusという元々用意されているコーパスを読み込んで利用しましたが、自分で好きな文章を取ってきてそこからコーパスを作成することも容易です。
例えば青空文庫からスクレイピングを行い、「宮沢賢治の文章に特有のパターン」や「芥川龍之介が頻繁に使う表現」を調べることもできます。
コーパスの作成はWord2Vecの本質からは少し逸れてしまうのでこちらの記事では詳しく解説しませんが、Python上でMeCabというライブラリを読み込むことで簡単に行えます。
興味がある方は、ぜひ試してみてください。
最後に
実を言えば、LLMの内部でも単語はベクトル化された上で処理されており、遥かに複雑ながらも実は近い基本思想で動いています。
Word2Vecに理解することは、結果としてLLMについての理解を深めることにも繋がるのです。
LLMをはじめとする生成AIが非常に便利な時代だからこそ、あえてLLMと異なるさまざまな技術にふれてその仕組みへの理解を深めたり、LLMが苦手とする分野をそれらの技術にカバーさせたりする選択肢を持つことは大切だと思います。
また、Word2Vecで生成したプロンプトをLLMに投げて処理させるなど、工夫次第でこれまでになかったようなツールを開発できる可能性もあります。
皆さんも基本的な技術と最新の技術を組み合わせて、より奥深い言語処理の世界へと飛び込んでみませんか。
